

こんにちは。
koma です。
先日、ベイズ統計学というものに遭遇しました。
迷惑メール判定の機械学習モデルの「ベイジアンフィルター」(メールフィルター)などで世の中では当たり前の話のようですが、私は全く知らなかったので、これはすごい!と感動しました。
ベイズと言えば学校で習った「ベイズの定理」を思い出します。
病気の陽性検査について考えます。
ある病気が流行していて、1% の確率で病気に罹患しています。
検査では病気に罹患している人の 90% に陽性判定が出ます。
また、病気に罹患していない人の 20% に陽性判定が出ます。
検査をした人から無作為に1人を選んだとき、その人が陽性判定が出ていて実際に罹患している確率は何%でしょう。
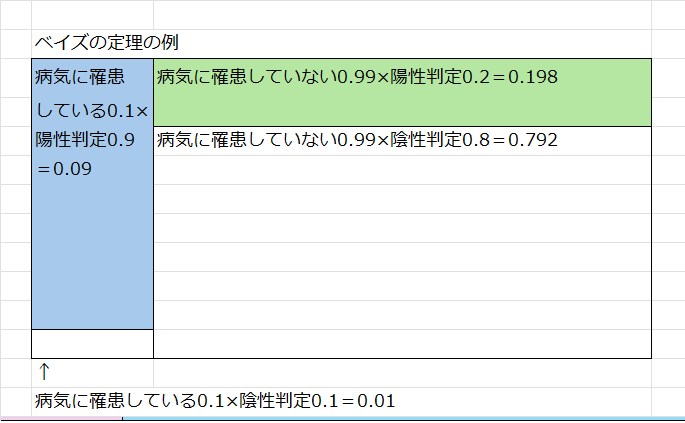
図を描きました。まず病気に「罹患している/していない人」がいる2つの世界線に分けます。
つぎに、先ほど2つに分けた世界線からさらに「陽性/陽性判定」の2つの世界線に分けます。
これで4つの世界線が生まれましたね。さてここからが本題です。
自分がこの検査で陽性が出てしまったとします。
その場合、「陰性判定が存在する」2つの世界線はなくなってしまうので消します。
そして残っている世界線(の面積)を整えます(正規化)
すると、「陽性判定が出ていても、本当に罹患しているのは4.3%」と分かります。
自分だったら少しホッとします。たぶん。

ビジネスでは、神のみぞ知る「真の世界」を当てにいくというよりは、意思決定につながる材料に確率を利用するイメージです。
いわゆる推測統計では、頻度論に基づき仮説検定をやりますね。
仮説検定の手順はこんな感じです(間違ってたらすみません)
- 対象となる仮説A(帰無仮説)と「Aではない」という仮説B(対立仮説)を用意します
- 稀(確率α)にしか見られない現象(X)が観測できるか調査をします。
- 現象(X)を観測⇒Aは間違いなので棄却し、Bを採択
- 現象(X)を観測されない⇒Aは間違いとは言えないので棄却できずAを採択
もちろん、この採択が間違っている可能性(確率α)は承知の上となるため、何回も繰り返すうちに採択を間違える可能性もありますが、それも込々で受け入れることになります。
仮説検定で一番気になるのは、棄却できるか?がポイントになるということです
例えば、サイトAとサイトGに広告を1000回出した結果、サイトAで1回、サイトGで100回クリックしてくれたら、今後はサイトGで行こうと意思決定ができる(棄却できる)と思います。
でもこの差が大きくなく、有意差がない(棄却できない)場合は、どっちかわからないので決められなくなってしまいます。
ベイズ推定の場合は、仮説検定のような有意水準の設定がありません。そのため、”とりあえず””おおよそ”といった推定ができます。
サイトAとGの「どちらか一方で」というよりは、どちらも可能性があるとして、サイトAでの効果が「高くなる可能性は●●%」という結果になります。
そんな主観確率でいいのか!?と言われ一時は下火だったベイズ統計ですが、「確率の確率」を材料に、意思決定ができる!という点で主流になりつつあるようです。
ベイズ推定を調べていると不思議な気持ちになっていくので、沼りたい方は是非!
参考URL
pythonによるベイズ統計モデリング入門 ~ MCMCで線形回帰をやってみる ~
余談
上述の例を計算するようなとっても小さいサイズのPythonコードを見せてもらったのですが、コードがわかるだけでなく、数学(統計)も必要なんだな、と感じました。
おしまい。
ここまで読んでいただきありがとうございました。




