
近年の生成AIモデルはものすごい速度で成長しており、モデルの出来ばえを ベンチマーク という共通物差しで測ることが標準になっています。ベンチマークは、ジャンル毎に多数存在(例:一般的なタスク、数学)しますが、私個人としては、コーディング用途が大半なため、開発関連のベンチマークについて調べました。
ベンチマークの定義と目的
ベンチマークは「決められた課題セットを用意し、自動もしくは半自動でモデルのアウトプットを採点する評価基盤」です。
ランキング形式のダッシュボードが公開されているケースが多く、開発用途でAIを導入したい場合のモデル選出の参考になります。
開発関連の代表的なベンチマーク
| ベンチマーク名 | 内容 | Web関連タスク |
| HumanEval | 164 問の手書き Python 関数問題 ※GPT-4以降の世代ではほぼ満点近くになるため差が少ない | なし |
| MBPP | 約 1,000 問の初-中級 Python 問題 | なし |
| BigCodeBench | HumanEvalの改良版 | なし |
| SWE-Bench | GitHub 実 Issue-PR を 2,294 件収録し、テスト通過で採点 | あり |
| SWE-Bench Multilingual | SWE-BenchをJava/JS/TS/Go など 21 リポジトリに拡大 | あり |
現状では、現実的なWeb開発タスクと親和性があるSWE-Benchが、コーティング能力の指標としてよく用いられる傾向にあります。
ベンチマークの確認について
各ベンチマークはリーダーボードやダッシュボードを公開していることが多いです。先述したSWE-Benchもリーダーボードがあります。
各ベンチマークのリポジトリでモデル毎の検査結果を確認することも可能です。
が、比較という意味では視認しにくいのと、人気の大規模言語モデルを単純比較したいだけの場合は使いにくいため、Epoch AI等、まとまった専用のサイトを見るのが現状では分かりやすいかなと思います。
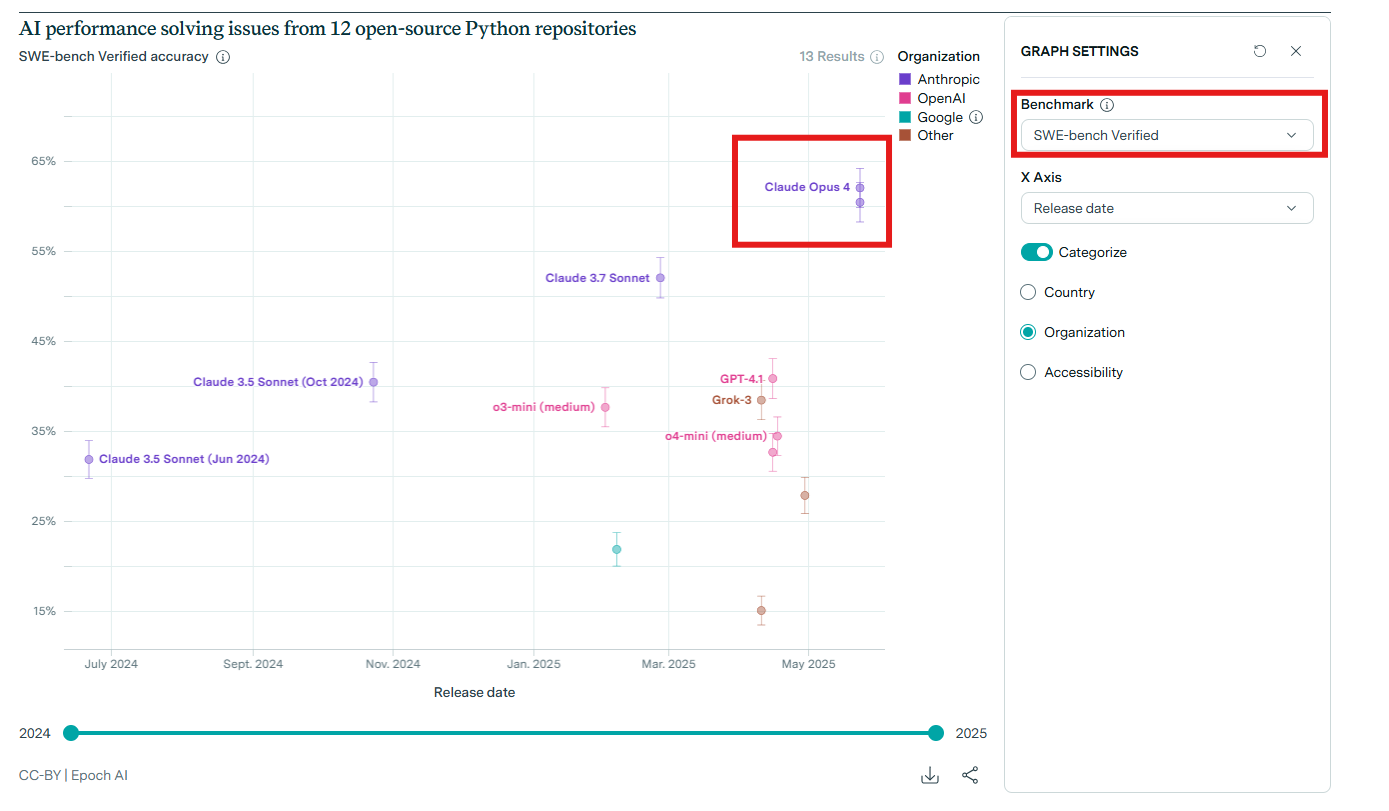
試しにEpoch AIのダッシュボードでSWE-Benchを確認してみると、5月23日に発表されたClaude4 Opusが高いスコアを出していることが分かります(Gemini 2.5 Proは現状プレビュー版なのでダッシュボードに掲載していないようです)
というわけで、こちらの動向は随時追っていきたいと思います。
今回は短いですが以上となります。(可能であれば何かしらのハンズオンをやろうと思いましたが次回以降に見送ります)



